我的第一次edusrc挖掘过程
- src
- 2023-08-14
- 8461热度
- 1评论
说来也是头疼,挖了好几天才挖到的,说来也是幸运哈哈,弱口令加源码和敏感信息泄露
开始肯定是确定目标,到全国漏洞排行榜 | 教育漏洞报告平台 (sjtu.edu.cn)去找
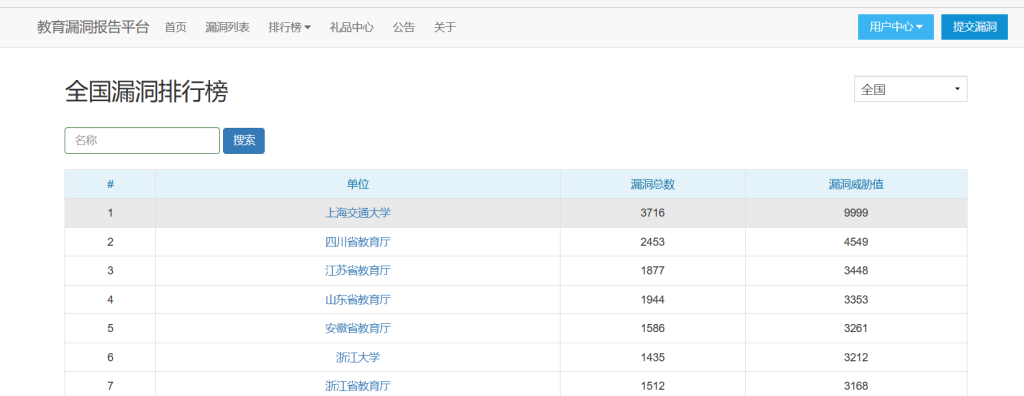
有人会说,这么多选哪个呢?我是从第200个开始挖的
这里分享一个脚本,可以爬下页面所有的目标
import requests
from lxml import etree
def schoolname(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
with open("edusrc学校.txt", "w", encoding="utf-8") as file:
for i in range(1, 208):
pageurl = url + str(i)
try:
req = requests.get(pageurl, headers=headers, verify=False)
req.raise_for_status()
tree = etree.HTML(req.text)
res = tree.xpath('//td[@class="am-text-center"]/a/text()')
file.write("\n".join(res) + "\n")
print(f"第 {i} 页爬取完成")
except requests.exceptions.RequestException as e:
print(f"第 {i} 页爬取出现异常:{e}")
continue
# 示例用法,假设url为"http://example.com/page",请将其替换为您要爬取的网页地址
url = "https://src.sjtu.edu.cn/rank/firm/0/?page="
schoolname(url)效果是这样的
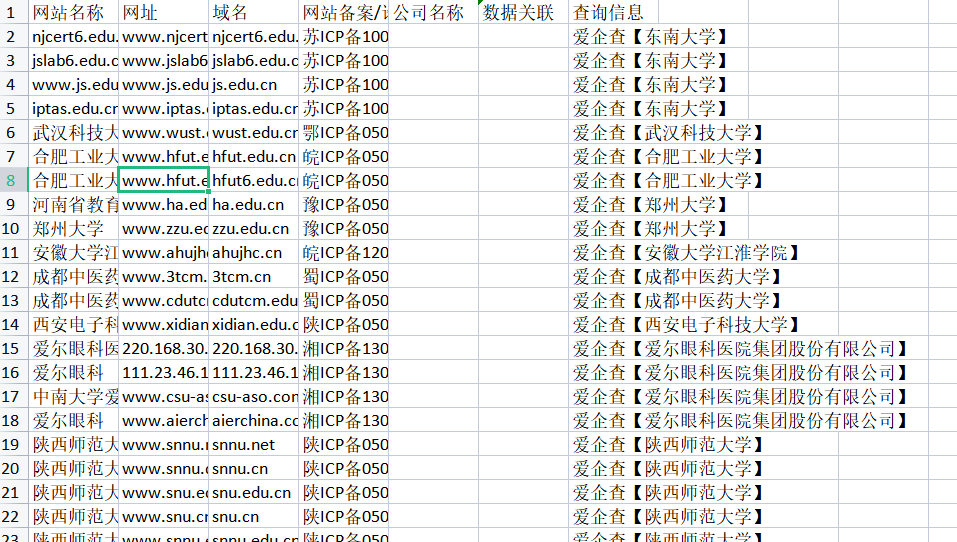
接下来便是信息搜集
先搜集他们的主域,这里推荐一个工具enscan,感觉挺好,可以批量处理
接下来子域名收集的话就是fofa、onforall、灯塔,都用搜集的比较全,然后整合去重。只留ip和域名即可

接下来可以去漏扫了,这里我使用的goby
扫之前要先导入poc,可以去github上找,比如红队poc
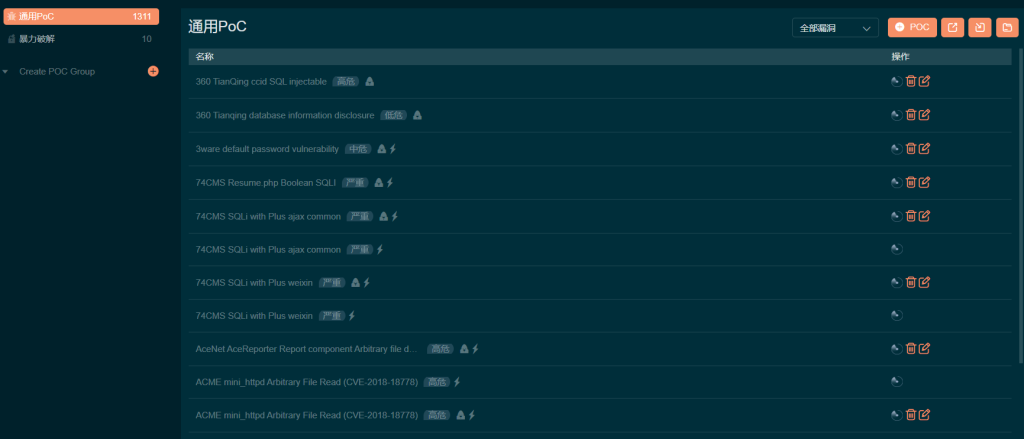
大概是这个样子,扫出来一个一个去复现试试,但大多数扫不出来啥,所以后来也不咋用了
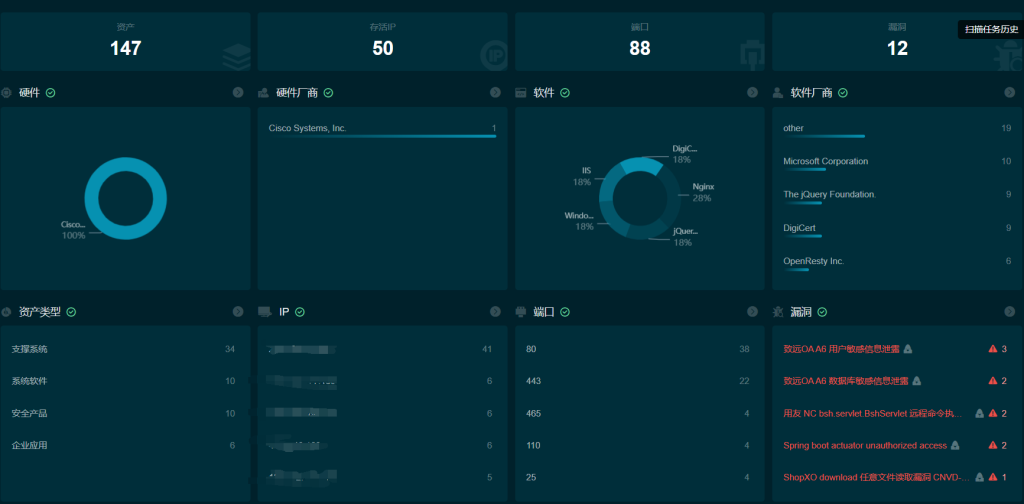
接下来就是一个一个域名一个一个看了,对于我这种小白真的很漫长,后来就盯着某一个漏洞去看,比如说你只盯着弱口令或者sql注入,那只要看登录口就。
这里有个小技巧,就是用fofa搜索
title="xxx大学"&&body="login"
或者
domain=“xxx.edu.cn”&&body="login"

之后出来的都是登录系统,直接点进去一个一个试就好
一般账号:admin 密码:admin、123456、admin123、admin888、admin666、888888、666666
如果都不行,直接下一个,如果没有验证码和账号锁定,那就可以试试爆破
在最终提交成功之前我也找到俩三个弱口令,交了但是审报告的人说没有什么危害,没啥可利用的都是一些普通用户。
害,大概看几个吧,也不枉我白忙活了


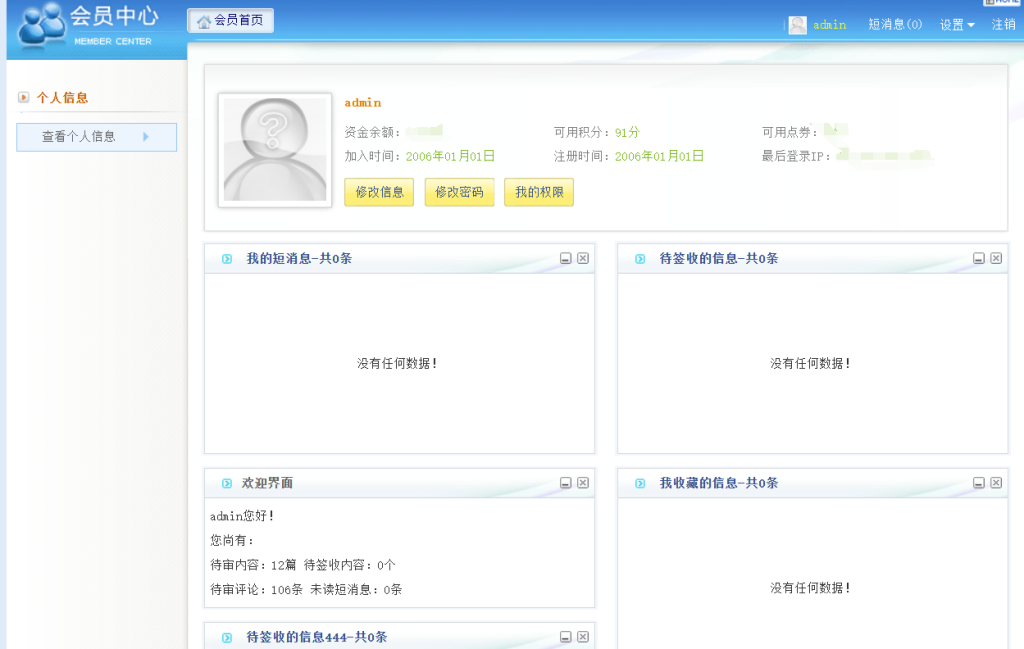
最后到某某大学的时候,真的有被吓到
弱口令进去了,还有大量源码和敏感信息泄露
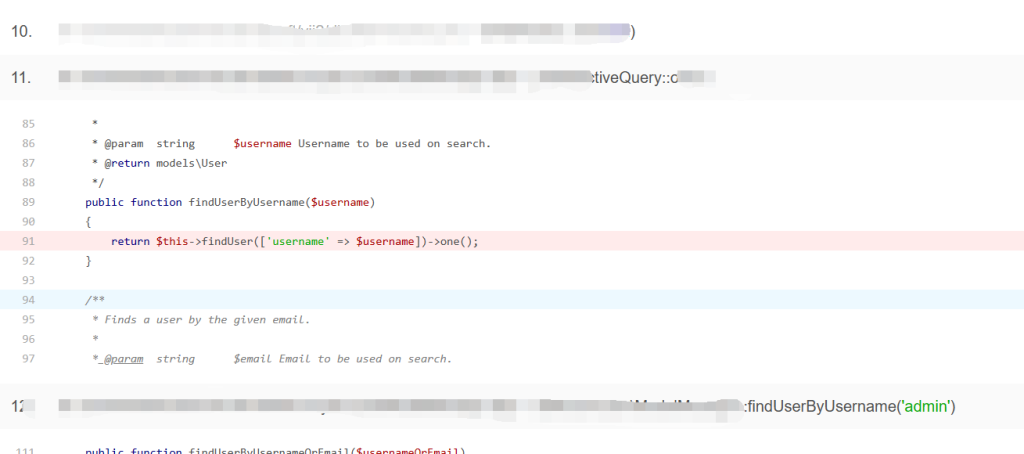
包括数据库ip和账密,要知道数据酷是可以远程连接的,数据库中可能包含用户的个人身份信息、联系方式、社交安全号码等敏感信息。泄露这些信息可能导致身份盗窃、欺诈和其他恶意活动。

最后交报告的时候,要标题只写校名,简要描述处不要写内容,要具体写出危害和利用。